Les algorithmes de recommandation
Avant toute chose, il nous faut tâcher d’expliquer le fonctionnement technique des algorithmes de recommandation. Ces derniers ont pour objectif de rapprocher, selon des critères définis (genre, type d’utilisateur ayant regardé…), deux objets (films, musiques, textes…). Pour être le plus clair possible, prenons un cas d’usage : admettons que l’on souhaite rapprocher tous les programmes ayant la même thématique dans le fonds de la RTS ; nous avons pour cela à notre disposition trois choses : une transcription, un résumé et des mots-clés définis à partir d’un thésaurus. Par différentes opérations mathématiques, on va transformer ces trois éléments en deux chiffres entre 0 et 1 (1). Ensuite, on place ces deux chiffres dans un espace vectoriel, c’est-à-dire dans un espace mathématique (voir image ci-après), le tout pour chaque archive. Les points qui sont proches sont ceux partageant des caractéristiques communes, puisque le chiffre qui a été calculé à partir de leurs métadonnées spécifiques est proche. Si l’on souhaite voir les documents similaires, il suffit de prendre tous les points proches dans le graphique (ou les personnes en suivant leurs traces en ligne ou données démographiques) (2).
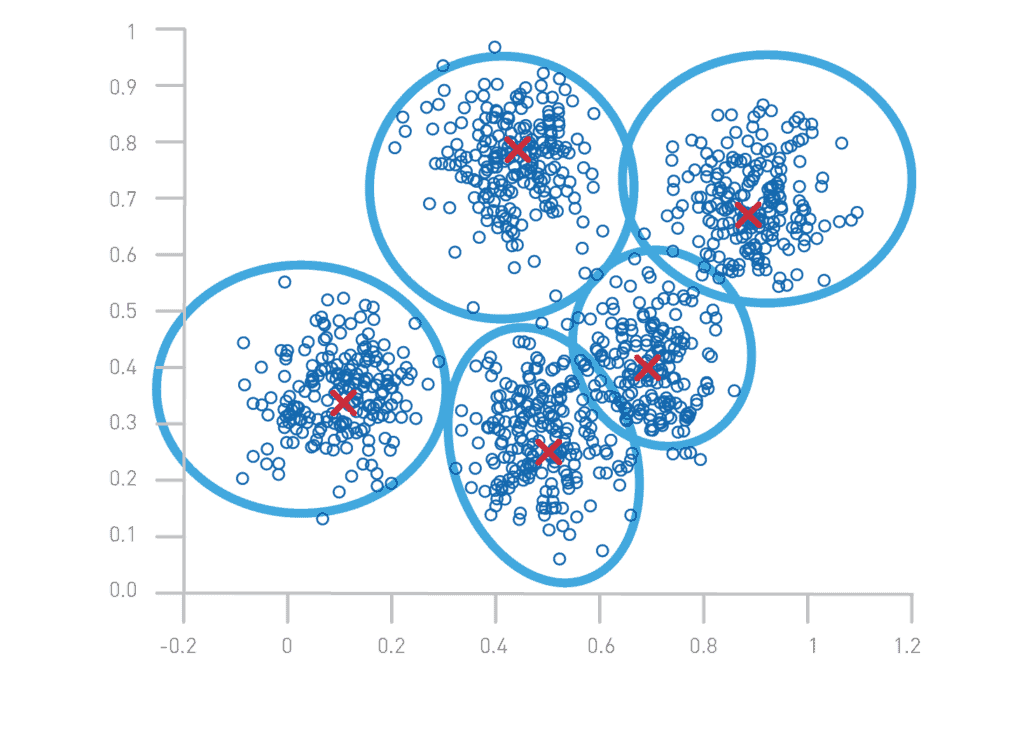
Cette description est évidemment très simplifiée : comment délimiter les catégories entre elles ? Comment faire en sorte que mon algorithme classe tous les documents selon des thématiques définies et pas uniquement en prenant en compte, par exemple, leur champ lexical ? Le principe des algorithmes de recommandation est tout de même globallement celui décrit. Il a été expérimenté dès 1975 par Salton et al.(cité par Arnaud Claes)(3). En 2002, Robin Burke proposait de les répartir selon cinq catégories (4) :
Recommandation collaborative : les contenus sont proposés en fonction des préférences de l’utilisateur et des comportements d’autres utilisateurs similaires.
Recommandation basée sur le contenu : Les suggestions sont faites en fonction des éléments similaires consultés par l’utilisateur dans le passé.
Recommandation démographique : les recommandations sont établies sur la base de critères démographiques tels que l’âge, le sexe et la localisation.
Recommandation basée sur un modèle de connaissance : ces algorithmes utilisent une base de connaissances, construite grâce aux réponses de l’utilisateur à des questions spécifiques, pour suggérer des objets en fonction des besoins exprimés.
Recommandation basée sur l’utilité : les contenus sont proposés en fonction de leur utilité pour l’utilisateur. Par exemple, si un arbre de décision pour le choix d’un produit prend en compte le coût, l’impact carbone et les notes des autres utilisateurs, un produit répondant à ces trois critères sera recommandé.
Sans rentrer dans le détail, chacune de ces catégories a des avantages et inconvénients : par exemple faire des recommandations basées sur le contenu nécessite beaucoup de données d’entraînement et de capter les traces de l’utilisateur, les recommandations basées sur l’utilité sont statiques, etc. C’est pourquoi elles sont souvent combinées, c’est par exemple le cas de Netflix qui utilise huit algorithmes différents, chacun répondant à un cas d’usage spécifique (5). Ce dont ces catégories témoignent, c’est aussi de deux visions : la première suppose que l’utilisateur peut explicitement donner ses préférences et la seconde, dite béhavioriste, suppose qu’il faut observer ses actions pour lui proposer du contenu (6). On observe clairement que la seconde vision décrite est celle qui est la plus représentée aujourd’hui, et ce, car les créateurs des algorithmes ont compris que « l’utilisateur n’est pas toujours la source la plus fiable pour éclairer ses propres intentions » (7). Force est de constater l’incroyable puissance de ces algorithmes quand on parle de découvrabilité, ainsi, si l’on prend l’exemple de Spotify et ses 80 millions de titres au catalogue, on peut noter que les playlists générées par algorithme de recommandation « découvertes de la semaine » jouent bien leur rôle. Elles auraient, en effet, permis — quelques mois après leur lancement — à quarante millions de personnes de consulter 5 milliards de morceaux nouveaux (8). Mais si le potentiel est immense, les enjeux le sont aussi, et notamment la transparence : comment savoir pour quelle raison tel contenu m’a été recommandé ? Surtout quand on voit à quel point les recommandations sont parfois grossières et fruits de clichés tenaces. Ainsi, en 2016, April Joyner, journaliste afro-américaine spécialisée dans les nouvelles technologies, se plaignait d’avoir vu, de façon soudaine, un tiers de ses recommandations sur son compte Netflix inclure des femmes afro-américaines dans les rôles-titres et l’apparition d’une catégorie « African American Movies » sur sa page d’accueil. Elle y voit un écueil majeur : l’invisibilisation, si l’utilisateur ne cherche pas à regarder un film de ce type et n’est pas catégorisé comme probablement de cette communauté (April Joyner vit à Harlem) (9), il n’en verra jamais (10).
On a donc des algorithmes qui, clairement, offrent un potentiel énorme de découvrabilité, mais qui, s’ils sont utilisés à des fins commerciales, finissent par réduire le champ de la découverte. Pour que les institutions patrimoniales, et plus largement les acteurs publics, puissent s’emparer du potentiel de ces algorithmes tout en évitant les problèmes posés, on a depuis quelques années vu émerger la notion d’Algorithme de service public dont nous tâcherons d’observer les différences fondamentales avec ceux mis en œuvre par les acteurs privés.
La notion d’Algorithme de service public : “prenez les commandes”, l’algorithme de recommandation de Radio France
Même si la société nationale de radiodiffusion française n’est pas un acteur patrimonial, l’ambition de son algorithme de recommandation est comparable à ceux évoqués par Irène Bastard et Arnaud Laborderie dans un article de juin 2023 réfléchissant à la mise en place d’un tel dispositif sur Gallica, la bibliothèque numérique de la Bibliothèque nationale de France (11). C’est-à-dire : augmenter le taux de la collection qui est consultée par les individus (48 % sur Gallica) (12) ; améliorer les rebonds entre les items (seuls 1 à 3 documents consultés par session en moyenne sur Gallica) (13) dans des collections où il est difficile de se repérer tout en évitant les écueils des algorithmes de recommandation commerciaux : Bulle de filtre, effets de viralité (quelques contenus reçoivent tous les clics), manque de transparence, perte de contrôle (14).
Ces ambitions et craintes, pensées avec les équipes éditoriales de Radio France, ont ensuite été transformées en cinq grands principes :
Mettre l’humain au cœur de la démarche de recommandation ;
Être totalement transparent ;
Favoriser la découverte et la curiosité tout en restant efficace ;
Laisser le contrôle à l’auditeur (16).
La différence fondamentale avec les algorithmes de recommandation privés est ici l’humain : il est au cœur de la démarche de recommandation (équipe éditoriale et créatrice) ; il peut comprendre pourquoi tel contenu lui a été proposé et il peut refuser qu’on l’oriente algorithmiquement et orienter l’algorithme (en lui indiquant par exemple de favoriser une émission en particulier) : le tout, pour favoriser sa découverte, car aucun humain ne pourrait naviguer dans les deux millions d’heures du catalogue de Radio France pour recommander à chacun le programme qu’il est susceptible d’apprécier. La notion d’Algorithme de service public n’est donc pas tant technique ; certes les données d’usage (traces ou logs) collectées sont réduites ; certes aussi les algorithmes publics n’utilisent pas ou peu de données démographiques, mais ce qui est fondamentalement différent c’est qu’ils placent l’humain au cœur de leur démarche, il garde le contrôle sur ce qu’il voit, comprend pourquoi il le voit et peut décider de stopper à tout moment. Il reste donc le « pilote » de sa navigation (18), ce qui constitue, si l’on suit l’analyse d’Olivier Ertzscheid, un retour en arrière : « Longtemps les technologies nous ont placées en situation de pilotage, avant de nous reléguer au rang de copilote, puis en nous laissant copilote, mais en supprimant le pilote au profit d’une seule fonction de pilotage automatique, et nous voilà désormais simplement, inexorablement, irrévocablement… passagers. Passagers par ailleurs exposés à la permanence d’un contrôle identitaire, et passagers sans autre bagage que l’acceptation naïve d’imaginer que nous pourrions encore être maitres du choix de notre destination. » (19)
Et c’est peut-être parce que Radio France est déjà un acteur majeur de la découvrabilité culturelle au travers de ses antennes, que la notion d’algorithme au service du public – où l’humain est au cœur de la démarche – y a été si bien comprise. Pensons par exemple à FIP (France Inter Paris), radio de l’éclectisme musical diffusant plus de 40 000 titres différents par an (20), et dont le directeur écrivait en 2023 qu’il possédait le meilleur algorithme du monde : « Pourquoi ? Tout simplement, car il est humain. Chaque jour, nos programmateurs partent d’une page blanche et programment — manuellement — des tranches de vie musicale dans lesquelles toutes les musiques se doivent de se mélanger »(21).
Notes
- Id., Record. La sérendipité sur Internet : égarement documenta… – Cygne noir – Érudit…, p. 14.
- F. Balle, Sérendipité…, 8 minutes 34 secondes.
- Dans notre cas, on utiliserait un algorithme de type TF-IDF qui calcule la fréquence (Term Frequency
[TF]) d’un terme dans un document en calculant le nombre de fois où le mot apparait divisé par
le nombre de mots totaux et sa rareté dans tous les documents (Inverse document Frequency [IDF]) en
calculant le logarithme du nombre total de documents divisé par le nombre de documents contenant le
mot, on fait ensuite TF * IDF. L’intérêt est d’identifier les mots signifiants importants pour un document
en réduisant l’importance des mots vides (« le », « et »…) [Explications fournies par Chat-GPT et
remaniées - Introduction to clustering | Machine Learning | Google for Developers, url : https : / /
developers.google.com/machine-learning/clustering (visité le 19/08/2024). - Arnaud Claes, Arnaud Claes – Algorithme de service public et autonomie critique : Etude des
effets de la contrôlabilité d’un algorithme de recommandation sur l’autonomie critique de ses usagers
| UCLouvain, thèse de doct., Belgique, Louvain-La-Neuve, 2022, url : https://uclouvain.be/fr/
facultes/espo/evenements/arnaud-claes.html (visité le 19/08/2024), p. 38. - Ibid.
- Ibid., p. 47.
- Ibid., p. 38.
- Ibid., p. 39.
- E. Durand, « Chapitre 5 – Le nouvel âge de la diversité », dans L’attaque des clones, Paris,
2016 (Nouveaux Débats), p. 73-88, url : https : / / www . cairn . info / l – attaque – des – clones —
9782724619805-p-73.htm (visité le 19/08/2024), § 2. - About Me, oct. 2017, url : https://www.apriljoyner.com/ (visité le 19/08/2024).
- La question des bulles de filtre sera traitée dans la partie 3
- Irène Bastard et Arnaud Laborderie, La découvrabilité des collections numériques patrimoniales
sous l’angle des usages de Gallica, Text, juin 2023, url : https : / / bbf . enssib . fr / matieres – a –
penser/la- decouvrabilite- des- collections- numeriques- patrimoniales- sous- l- angle- des-usages-de-gallica_71295 (visité le 19/08/2024). - Ibid.
- Ibid.
- Bastien Luneteau et Valentin Lecomte, Penser la découvrabilité des contenus culturels, juin 2023,
url : https://www.bnf.fr/fr/agenda/penser- la- decouvrabilite- des- contenus- culturels
(visité le 19/08/2024). - Ibid.
- O. Ertzscheid, GPT-4 Omni : Chat Pantin(s). Mai 2024, url : https : / / affordance .
framasoft.org/2024/05/gpt-4-omni-chat-pantins/ (visité le 19/08/2024). - Ibid.
- La rentrée de Fip, 2023, url : https://www.radiofrance.com/sites/default/files/2022-
08/rentree_2223_dp_fip_26082022.pdf (visité le 19/08/2024). - Ibid.
Bibiliographie
Bastard (Irène) et Laborderie (Arnaud), La découvrabilité des collections numériques
patrimoniales sous l’angle des usages de Gallica, Text, juin 2023, url : https://
bbf . enssib . fr / matieres – a – penser / la – decouvrabilite – des – collections –
numeriques – patrimoniales – sous – l – angle – des – usages – de – gallica _ 71295
(visité le 19/08/2024).
Cardon (Dominique), « Dans l’esprit du PageRank. Une enquête sur l’algorithme de
Google », Réseaux, 177–1 (2013), p. 63-95, doi : 10.3917/res.177.0063.
Claes (Arnaud), Arnaud Claes – Algorithme de service public et autonomie critique :
Etude des effets de la contrôlabilité d’un algorithme de recommandation sur l’autonomie
critique de ses usagers | UCLouvain, thèse de doct., Belgique, Louvain-La-Neuve,
2022, url : https : / / uclouvain . be / fr / facultes / espo / evenements / arnaud –
claes.html (visité le 19/08/2024).
Durand (Emmanuel), L’attaque des clones : la diversité culturelle à l’ère de l’hyperchoix,
Paris, 2016 (Nouveaux débats, 44).
Ertzscheid (Olivier), Économie des biens culturels, cours de 2e année de DUT information
et communication option métiers du livre et du patrimoine, 2019.
— GPT-4 Omni : Chat Pantin(s). Mai 2024, url : https://affordance.framasoft.
org/2024/05/gpt-4-omni-chat-pantins/ (visité le 19/08/2024).
Ertzscheid (Olivier) et Gallezot (Gabriel), « Chercher faux et trouver juste, » ( juill.
2003).
Introduction to clustering | Machine Learning | Google for Developers, url : https:
//developers.google.com/machine-learning/clustering (visité le 19/08/2024).
La rentrée de Fip, 2023, url : https://www.radiofrance.com/sites/default/files/
2022-08/rentree_2223_dp_fip_26082022.pdf (visité le 19/08/2024).
Luneteau (Bastien) et Lecomte (Valentin), Penser la découvrabilité des contenus culturels,
juin 2023, url : https://www.bnf.fr/fr/agenda/penser-la-decouvrabilitedes-
contenus-culturels (visité le 19/08/2024).

Laisser un commentaire