Voir globalement : l’importance d’avoir une vue d’ensemble des collections
Comme décrit il y a quelques semaines, la digitalisation du patrimoine a créé des volumes de données immenses et a, dans le même temps, changé notre rapport au patrimoine qui est devenu plus intangible1, plus « virtuel ». Aux salles de lecture d’archives saturées des années 1980, ont succédé des sites web qui le sont tout autant — si ce n’est plus. Dans le cas du patrimoine audiovisuel, massivement numérisé dans les années 2000, les interfaces sont très souvent les seuls moyens d’accéder aux objets patrimoniaux. Cette nouvelle approche d’un patrimoine intangible, accessible par le biais d’interfaces web basées sur les métadonnées, change les pratiques et usages, notamment le sens de recherche. Là où les chercheurs démarraient aux niveaux hiérarchiques hauts (fonds, collections, etc.), les moteurs de recherche donnent aujourd’hui accès au niveau de la pièce directement, rendant difficile l’appréhension des collections dans leur ensemble et rejoignant le concept de « fatigue muséale »2. Les interfaces web classiques, une barre de recherche et des filtres à facettes viennent reproduire, et même amplifier, cette problématique de fatigue muséale ; les utilisateurs occasionnels étant souvent confrontés à un syndrome de la barre de recherche blanche. Sans vue d’ensemble sur les fonds, ils ne sont pas capables d’aller les explorer. C’est pourquoi, le concept d’interfaces dites généreuses est né3 ; elles partent du postulat que l’utilisateur n’est plus un chercheur en manque d’information, mais un flâneur qui souhaite découvrir le fonds. La priorité de telles interfaces, contrairement aux barres de recherche qui favorisent la « trouvabilité », est de favoriser la découvrabilité4. La visualisation de l’information (ou data visualization) prend alors une importance nouvelle puisqu’elle peut permettre d’améliorer la découvrabilité des fonds.
Prenons ici comme exemple l’expérience conduite par le laboratoire de recherche de la bibliothèque publique de New York « Le catalogue en réseau »5, dont l’objectif était de montrer la totalité du catalogue sur une seule image et de voir les relations qu’entretiennent les objets entre eux, comme si le catalogue avait un bouton « voir tout »6.
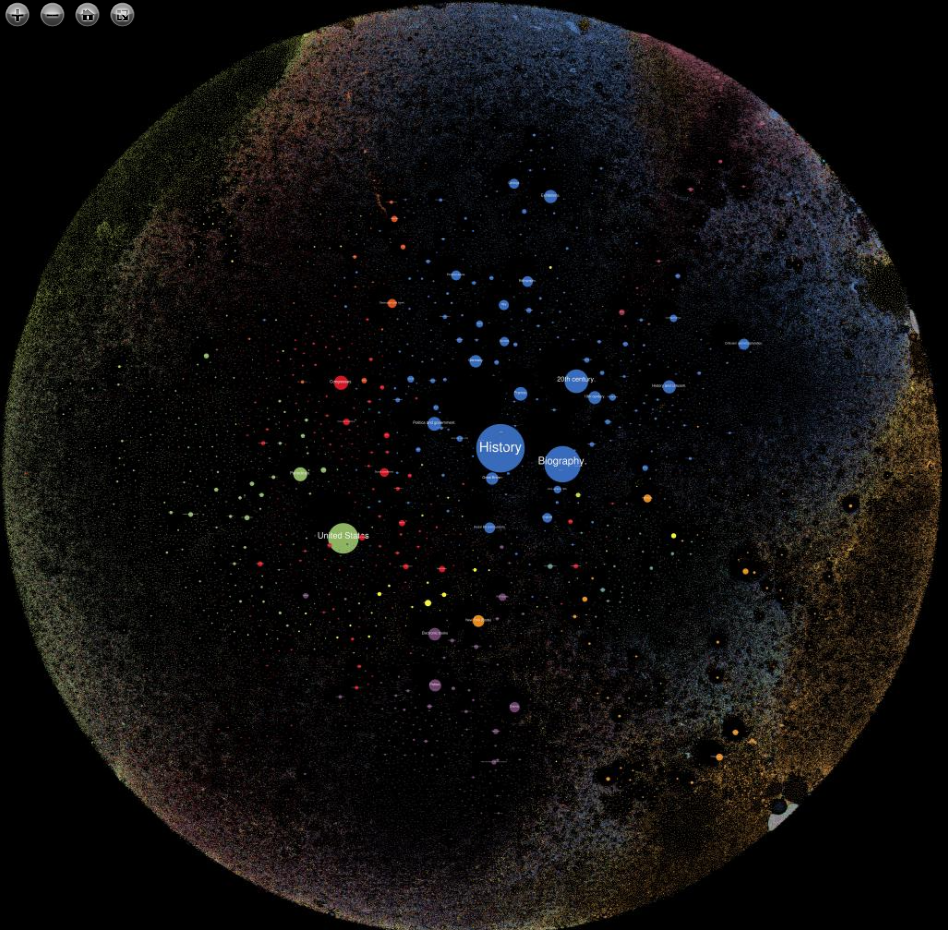
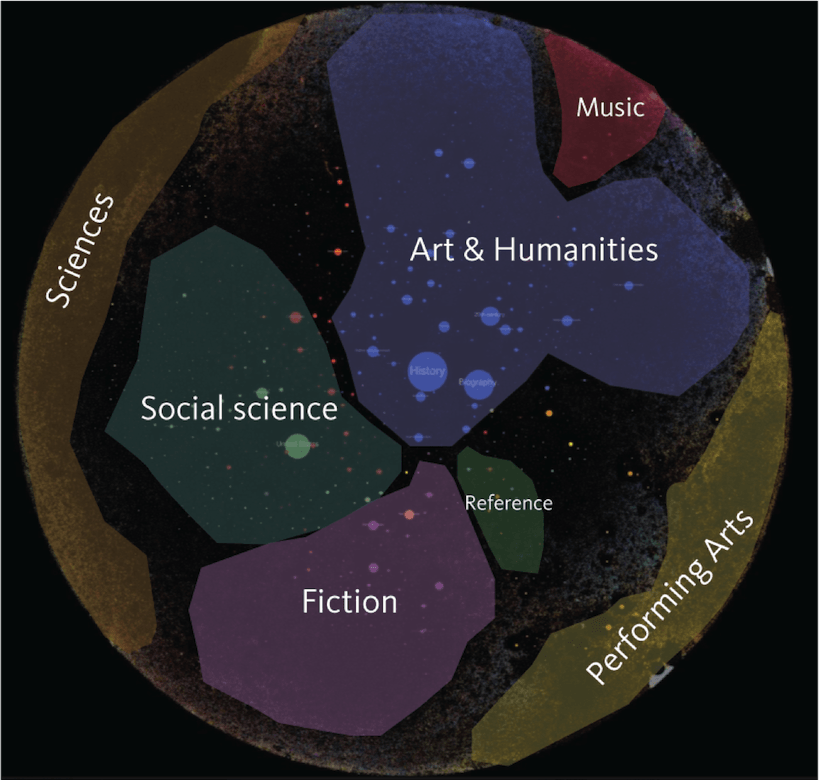
Techniquement parlant, cette visualisation utilise les descripteurs MARC d’indexation de chaque item et les affiche sous forme de points colorés : plus un point est gros, plus il y a d’ouvrages le concernant dans la bibliothèque publique de New York ; si deux sujets sont souvent mentionnés ensemble, par exemple Jeux Olympiques et sport, on en déduit qu’ils sont liés d’une manière ou d’une autre et ils se voient attribuer la même couleur.
Outre le fait qu’elle soit fascinante et que l’explorer et s’y perdre soit passionnant7, elle permet, d’un coup d’œil, de se rendre compte des pans de la collection très représentés et centraux ainsi que des liens sémantiques, parfois étonnants entre des entités. Cela permet de se rendre compte de ce qu’une bibliothèque, en tant que réceptacle du savoir à un instant donné, conserve le plus. La visualisation peut donc être, comme l’écrit Raphaëlle Lapôtre, « un moyen heuristique qui participerait à la production de connaissances »8. En plus de donner une vision d’ensemble et de favoriser la compréhension globale de la collection, elle permet d’en révéler de nouveaux aspects. On serait évidemment tenté de voir dans cette image une visualisation des connaissances, comme si une bibliothèque était le reflet du réel et des connaissances produites. Mais ce miroir est déformé : parce que le contenu d’une bibliothèque est le reflet des politiques documentaires de son époque ; parce que les données ne sont pas si fiables, qu’elles sont truffées d’erreurs humaines ; de choix d’indexation ; des migrations de données et des changements de vocabulaires. Par exemple, le mot tsunami n’est employé que depuis récemment, on lui a longtemps préféré « raz-de-marée »9.
Éclairons notre propos avec l’exemple de la RTS où durant notre stage on a voulu effectuer une démarche similaire pour proposer un outil de navigation sous forme de treemap hiérarchique en utilisant les “codes contenus” qui sont des métadonnées fournies pour chaque document renseignant sa thématique de façon hiérarchique, par exemple un téléjournal aura le code contenu “Actualité”.

Une fois la visualisation réalisée, nous nous sommes rendu compte qu’elle n’était absolument pas le reflet de ce qui était conservé à la RTS. D’abord, car seule une petite proportion des documents avait un code contenu renseigné (361 837 documents), ensuite car ce qui fait varier la taille des rectangles, qui est proportionelle au nombre d’émissions ayant le même code contenu, ne reflète pas la réalité du fonds, mais des politiques documentaires.On retrouve par exemple énormément d’actualité – ce qui est en partie vrai – mais elle est aussi beaucoup représentée, car c’est la seule, depuis les années 1980, à être archivée de façon systématique. Quant au sport, dont on pourrait s’étonner de la forte présence au regard de ce qui a été écrit plus haut, cela s’explique par une description assez détaillée des codes contenus pour le sport, qui est assez facile à catégoriser (selon la discipline), contrairement à d’autres type d’émissions ; par ailleurs, comme le sport est souvent acheté par la RTS, il est important qu’il soit bien décrit pour des questions de droits, les codes contenus sont d’ailleurs surtout utilisés pour cela. Comme la carte de la bibliothèque publique de New York était plus le reflet de son histoire institutionnelle et documentaire, cette visualisation est le reflet des pratiques documentaires de la RTS plus que de ce qui est conservé en son sein. Dans les deux cas, surtout à New York, l’objectif de donner une vision d’ensemble de la collection semble accompli. Les possibilités heuristiques offertes par la visualisation de données, une fois les spécificités et biais potentiels pris en compte, sont prometteuses. En effet, cela permet d’envisager de fournir aux utilisateurs des collections des clés de lecture différentes, qui feront l’objet de notre prochaine section.
Voir sous un autre angle : donner des clés de lecture différentes des collections
On vient de voir que la visualisation de l’information, en plus d’offrir une indispensable vue d’ensemble des collections, offre un potentiel heuristique nouveau. Elle permet en effet « d’opérer un “point de vue” sur un sous-ensemble de résultats pertinents afin d’en faciliter la compréhension »10. L’intérêt de visualiser des données est donc d’offrir aux regardeurs différentes clés de lecture11 d’une collection. On peut séparer ces clés de lecture en trois catégories (qui peuvent se cumuler) : vues multiples (listes, mosaïques, etc.) ; encodage spatial (cartes géographiques, diagrammes de réseau, etc.) et encodage temporel (frises chronologiques, animations)12. À chaque catégorie correspondent des possibilités interprétatives différentes, par exemple : un diagramme en réseau permet d’explorer la proximité entre des objets culturels, une animation permet de donner à voir les évolutions temporelles des objets13.
La multiplication des interfaces de visualisation offre aux utilisateurs un accès riche et non restrictif aux collections culturelles, ce qui permet d’explorer des ensembles de données vastes. Ce faisant, ces différentes interfaces sont des outils précieux pour exposer la richesse et la diversité des collections culturelles afin que les utilisateurs puissent naviguer entre différentes perspectives. Pour les qualifier, F. Windhager et al. parlent d’« interfaces généreuses ».14 qui se distinguent des interfaces classiques par une capacité à présenter de grandes quantités d’informations en soutenant les utilisateurs dans leurs tâches cognitives. De même qu’un bâtiment doit être généreux et offrir des espaces vides et des plafonds hauts pour être agréable à utiliser, les interfaces, en tant que substituts immatériels, doivent faire de même.
Elles doivent donc être conçues pour éviter la surcharge cognitive en offrant des représentations multiples des données, ce qui permet aux utilisateurs de construire une vision globale et cohérente des collections qu’ils explorent16. Elles se veulent des « anti barres de recherche », car, selon les auteurs, ces dernières sont construites selon deux suppositions préalables : le visiteur connait, au moins vaguement, ce qu’il cherche et il ne souhaite pas « s’engager dans la complexité de l’espace de recherche qui leur est caché »17.
Afin d’illustrer notre propos, nous mettrons en parallèle un exemple issu d’une réalisation pendant le stage (carte interactive des contenus archivés par la RTS) et le tableau de bord réalisé par la Bibliothèque du Congrès pour visualiser la presse numérisée18.
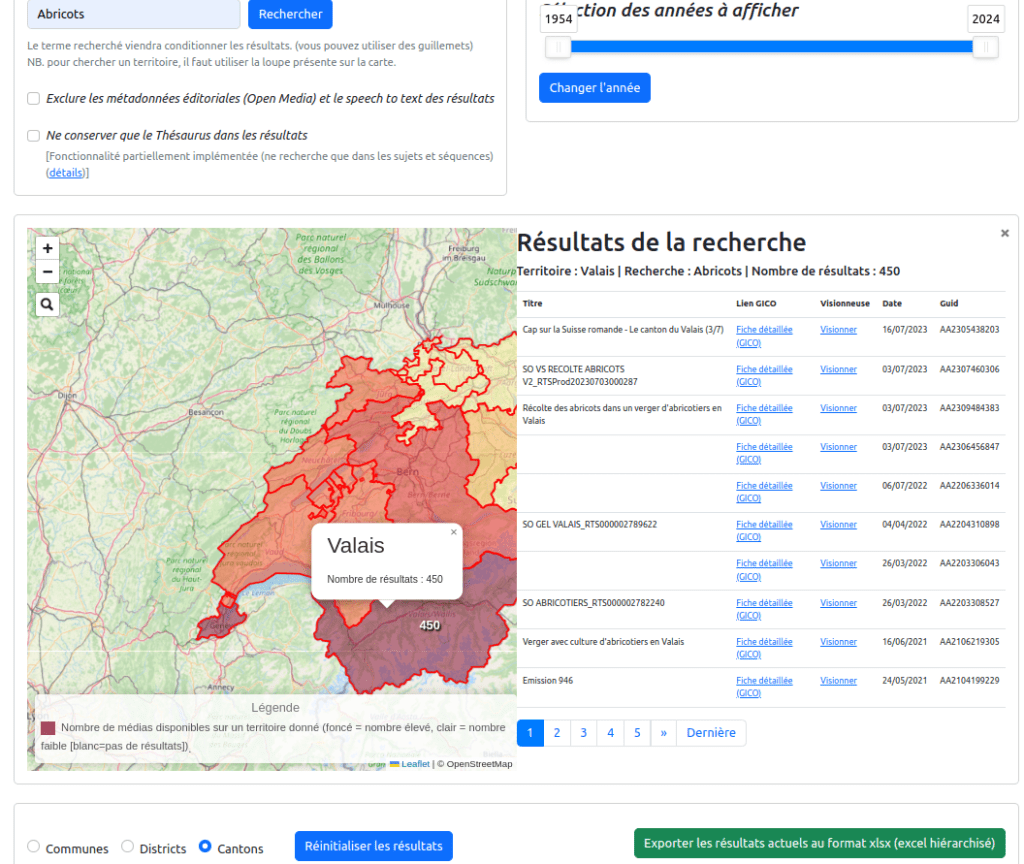
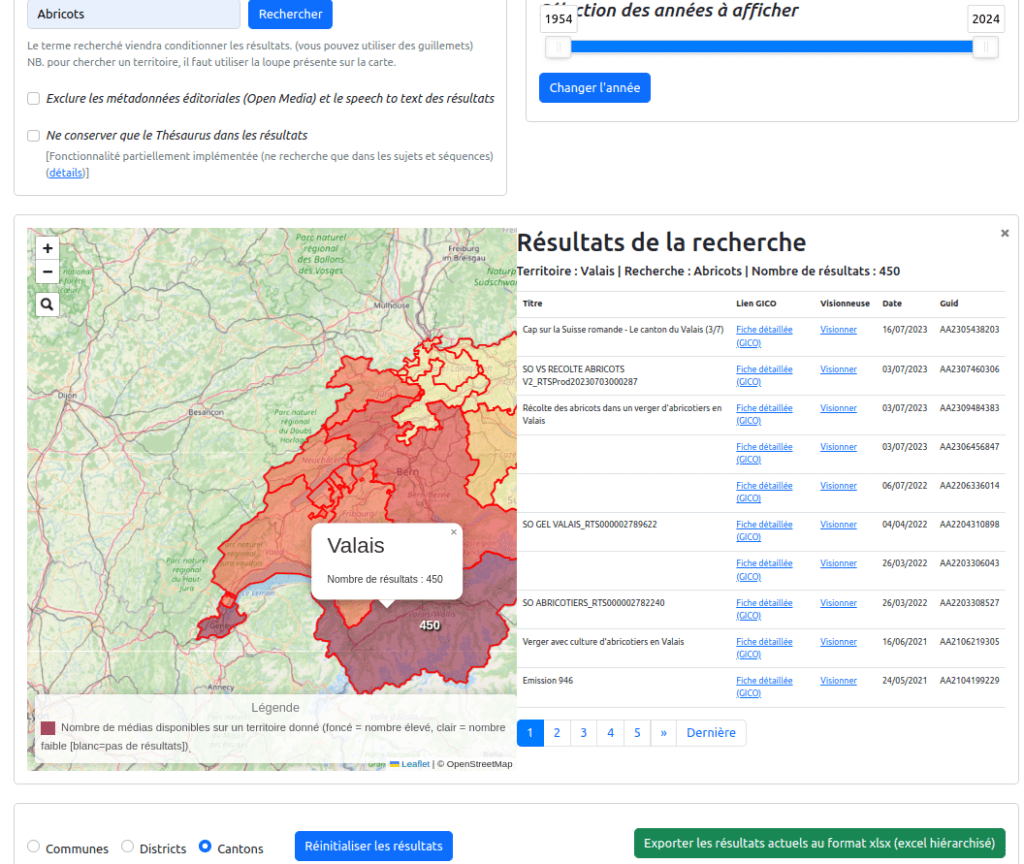
D’abord, donc, la carte interactive des contenus (visible sur cette page) qui se présente, comme son nom l’indique, sous forme d’une carte de la Suisse avec la possibilité de naviguer entre les différents niveaux territoriaux du pays : cantons, districts et communes. Elle permet, en un seul regard, d’observer les territoires pour lesquels la RTS conserve le plus d’archives et de cliquer sur ces derniers pour consulter les archives qui s’y réfèrent. Elle combine les niveaux de lecture spatiaux et temporels décrits plus haut en permettant aux utilisateurs de naviguer dans le temps pour observer les variations dans la collection. Par ailleurs, ils ont la possibilité d’inclure un terme de recherche pour observer la répartition géographique de ce terme. Par exemple, dans l’image ci-après, on a tapé « abricots » et on observe que le canton le plus représenté est le Valais19. Cette carte n’est donc pas uniquement un outil d’exploration, elle permet aussi de réaliser des statistiques à partir des recherches effectuées en proposant un export (au format Excel) de ce qui est visualisé. L’image est ici synoptique, elle permet de voir plusieurs temporalités et états dans le même temps, c’est un choix sémantique fort mais qui peu parfois être complexe pour l’utilisateur, c’est pourquoi d’autres projets préfèrent scinder les possibilités heuristiques en plusieurs visualisations. Tel est le cas de la bibliothèque du Congrès et de son tableau de bord.
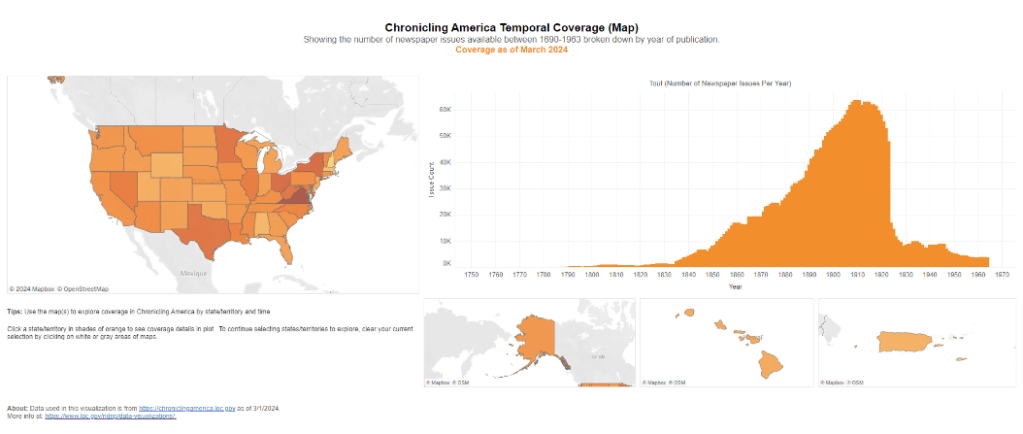
L’instutitution propose en effet un tableau de bord, lui aussi interactif. Il permet aux utilisateurs de voir le nombre de journaux numérisés disponibles dans chaque État. C’est là aussi une interface qui combine une lecture spatiale et temporelle, mais, ici, le choix a été fait de séparer ces deux clés de lecture, la carte permet de sélectionner l’État pour que l’utilisateur puisse visionner le nombre de titres de presse disponibles et numérisés à travers le temps. Cette interface ne permet, en revanche, pas de consulter directement les titres de presse.
On a donc ici deux approches similaires, mais avec des visées différentes, la première approche est plus du côté de l’interface de navigation dans les collections, la seconde est statistique. Dans les deux cas, on offre aux utilisateurs la possibilité de voir dans son ensemble un fonds extrêmement volumineux en proposant des clés de lecture variées. Soit elles sont combinées dans une seule visualisation à l’aide de filtres, soit elles sont séparées en deux visualisations différentes. Cette vision d’ensemble permet aux personnes consultant les fonds de ne pas tomber dans certains écueils. Par exemple, dans le cas de la RTS, étant une chaîne romande, la majorité des sujets concerne la région linguistique francophone. Si l’on souhaite effectuer une recherche sur des cantons italophones ou germanophones, ce ne sera pas l’endroit le plus pertinent. Ce type d’interface répond donc à de multiples problématiques : donner une vision d’ensemble et des clés de lecture différentes d’un fonds ; permettre une interprétation quantitative ; être utilisé dans des actions de valorisation tout en limitant le syndrome de la barre de recherche blanche. Par ailleurs, la multiplicité des filtres permet une granularité de navigation très importante donnant de nombreuses opportunités de se concentrer sur des documents spécifiques19. Combiner différentes clés de lecture (dans le cas de la RTS, nous avons ajouté à cette visualisation un knowledge graph visible plus bas) en prenant en compte le fait que chacune permet de capturer un aspect spécifique de la collection est donc une stratégie intéressante dans le cadre d’objets culturels complexes. Par ailleurs, cela permet de créer des possibilités pour les utilisateurs de faire des découvertes par sérendipité, car ce type d’interface les laisse « flâner » dans les collections comme le notent Thudt et al.20. En revanche, comme le notent Florian Windhager et al., réaliser des interfaces généreuses combinant de nombreuses visualisations et possibilités de filtrage peut recréer la problématique de fatigue muséale en créant ce que les auteurs appellent le « split attention challenge »21. Les interfaces, de même que les bâtiments, auxquels elle prétendent se substituer, doivent donc – tout en restant généreuses – ne pas proposer trop de niveaux de lecture et rester simples d’utilisation, car dans les deux cas, cela résulte en un usager perdu : dans l’immensité de l’espace physique ou virtuel (ici aussi, le site François-Mitterrand est éclairant).
Voir pour aller plus loin
Dans la section précédente, nous avons montré que les interfaces pouvaient permettre de se substituer aux bâtiments en proposant une vue d’ensemble des collections et une navigation dans cette dernière, à la manière des déambulations dans un lieu physique. Mais peuvent-elles permettre d’aller plus loin ? Peuvent-elles permettre de dépasser les capacités humaines en matière de découvrabilité ? Pour tenter de répondre à ces questions, nous allons explorer le projet de recherche Philherit présenté lors de la journée d’étude organisée par la Bibliothèque nationale de France le 20 juin 2023 « Penser la découvrabilité des contenus culturels »22 et le projet Impresso (projet d’exploration de corpus de la presse écrite [images et textes])185.
Comment poser la question de l’héritage dans le domaine de la philosophie de nouveau ? C’est la question que pose le projet Philherit. Pour y répondre, le corpus à analyser est extrêmement vaste, car la question était centrale au XIXe siècle23 du fait de sa proximité avec les questions de justice sociale entre autres. Ce corpus est constitué, par ailleurs, de sources très variées (périodiques, livres, journaux, etc.) et dans toutes les disciplines (économie, philosophie, etc.) réparties en sept bases de données textuelles extraites depuis Gallica. Le texte est ensuite réparti en différents thèmes identifiés par trois mots-clés grâce à l’intelligence artificielle (BERT)24. Ce qui est intéressant ici, pour revenir à la question des interfaces, c’est la mise en place d’un nuage de mots qui reprend les thèmes générés par l’intelligence artificielle et les donne à voir de façon synthétique : plus un mot est représenté dans le corpus, plus il sera gros dans la visualisation, ce qui permet de dégager de grands thèmes et d’aller consulter les ouvrages essentiels25. Mélanie Plouviez, dans son intervention, dégage trois impacts de l’utilisation des interfaces pour l’amélioration de la découvrabilité du corpus : premièrement, l’accélération de l’analyse, qui était avant réalisée sur Excel manuellement et est désormais possible d’un seul coup d’œil sur l’interface ; deuxièmement, l’amélioration de l’analyse dite « hypertextuelle », c’est-à-dire de l’exploration des liens entre les documents ; et, troisièmement, l’amélioration de la sérendipité26. La chercheuse conclut son intervention en citant Michel Foucault qui, dans son “archéologie du savoir”27, définissait les archives comme une « masse discursive » à laquelle les humanités numériques auraient mis fin tout en permettant de faire émerger de multiples points de vue d’une même collection grâce à diverses interfaces28.
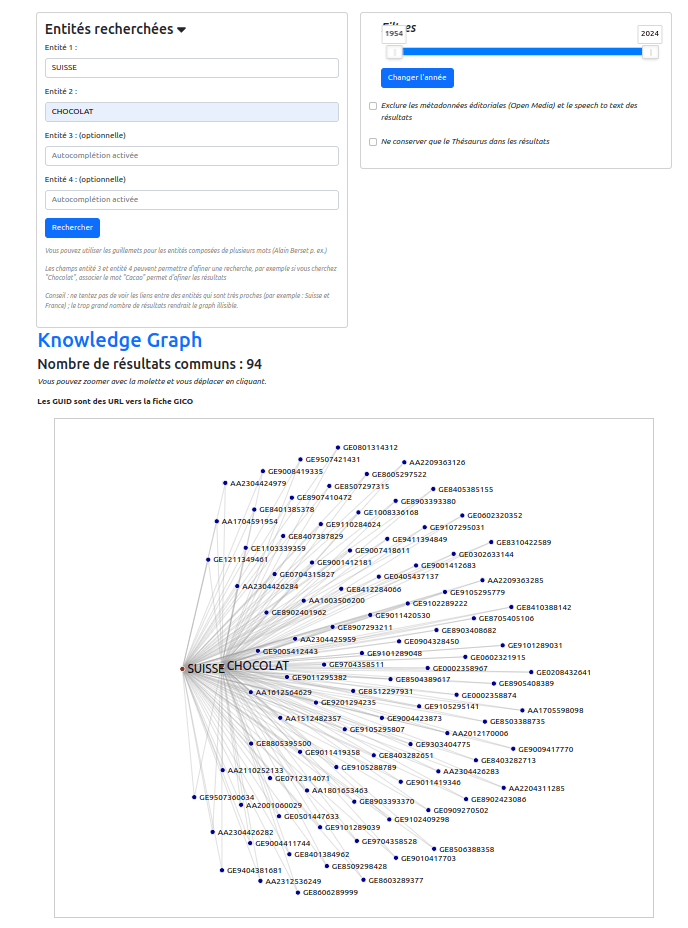
Les interfaces permettent-elles de dépasser les capacités humaines uniquement dans le cadre de projets spécifiques et de cas d’usages précis ? Attardons-nous sur le projet Impresso, dont l’objectif est d’améliorer la découvrabilité de la presse numérisée suisse et luxembourgeoise (donc en 4 langues)29. Il est mené par une équipe interdisciplinaire d’historiens, linguistes et informaticiens ainsi que des designers — essentiels pour la réalisation d’interfaces efficaces30. Ici, en plus de répondre à des cas d’usages « de chercheurs », le projet tente d’être accessible et utile pour les non-spécialistes en répondant à cinq cas d’usages : récupération du contenu utile, compréhension et contextualisation, comparaison des résultats, exportation pour analyse et transparence (documentation du code) et explicabilité de ce dernier31. L’interface répond donc à ces cas d’usages en offrant notamment la possibilité pour ses utilisateurs, une fois un terme recherché, de compléter leur recherche. Soit de façon thématique, avec des personnalités liées, ou bien des collections liées ; sans tenir compte de la langue de leur recherche.

Elle permet aussi de voir les textes et images similaires pour un sujet donné et de voir sa distribution dans le temps en suivant le principe des n-grams32. Enfin, elle permet de comparer différents résultats pour observer leur traitement dans la presse. Par exemple, on peut choisir d’observer les résultats communs entre « abricots » et « Valais », et on se rendra compte que l’année du pic observé (1953) correspond à la « révolte des abricots »33.

Il semble, à en lire les évaluations des utilisateurs, que les fonctionnalités proposées et l’interface soient non seulement faciles d’accès, mais permettent en outre une grande finesse dans l’exploitation de ce type de corpus textuel. Par ailleurs, les auteurs concluent en énonçant le fait que les chercheurs déjà habitués aux recherches « data-driven » étaient très positifs sur les possibilités d’export et d’exploitation offertes, de même que les utilisateurs moins connaisseurs34.
Au regard de ces deux exemples, on peut noter que la création d’interfaces généreuses, tout en permettant de dépasser les capacités humaines des chercheurs (Philherit l’a bien montré), peut aussi être un excellent vecteur de valorisation des collections pour le grand public. Il semble donc que la création de tels outils pourrait être placée du côté des institutions, car, et Impresso le montre bien, s’ils sont bien faits et offrent de nombreuses possibilités allant de la plus simple, faire une recherche ; à la plus complexe, exporter les données d’une visualisation au format JSON34 pour les exploiter. Ils servent des publics très divers et permettent d’éviter aux chercheurs de créer, de leur côté, des outils dédiés. Ils peuvent alors réutiliser ceux proposés par les institutions pour servir leur cas d’usage ou les réadapter en utilisant les données fournies. Les auteurs de l’article « transparent generosity » sur Impresso notent toutefois un certain nombre de limitations à la mise en place de tels outils : silos institutionnels et d’information (causés par des restrictions légales souvent), doublons et mauvaises qualités des données notamment de l’OCR35, mais aussi, manque d’interfaces proposant aux chercheurs de découvrir les fonds pour en tirer d’éventuels questionnements36. Travailler à la correction de ces limitations, notamment celles concernant les données en elles-mêmes, peut aussi permettre aux institutions de gérer de façon plus efficace leurs fonds en ayant une approche dite data-driven comme évoqué plus haut.
Notes
- F. Windhager, Paolo Federico, Gunther Schreder, Katrin Glinka, Marian Dork, Silvia Miksch et
E. Mayr, « Visualization of Cultural Heritage Collection Data : State of the Art and Future Challenges »,
IEEE Transactions on Visualization and Computer Graphics, 25–6 (1er juin 2019), p. 2311-2330, doi :
10.1109/TVCG.2018.2830759, p. 1. - B. I. Gilman, « Museum Fatigue »…, pp. 62-72.
- F. Windhager, S. Salisu, G. Schreder et E. Mayr, « Orchestrating Overviews : A Synoptic Approach
to the Visualization of Cultural Collections », Open Library of Humanities, 4–2 (13 août 2018),
p. 9, doi : 10.16995/olh.276, pp. 5-6. - Jeffrey J. Shen, A Generous Interface for the Discoverability of Text Collections, Accepted :
2023-07-31T19 :38 :10Z, Thesis, Massachusetts Institute of Technology, 2023, url : https://dspace.
mit.edu/handle/1721.1/151417 (visité le 19/08/2024), p. 18. - Raphaëlle Lapôtre, « Visualiser les données du catalogue », dans Vers de nouveaux catalogues,
ISSN : 0184-0886, Paris, 2016 (Bibliothèques), p. 37-47, doi : 10.3917/elec.berme.2016.01.0037, §20
à §26. - Matt Miller, The Networked Catalog | The New York Public Library, 31 juill. 2014, url : https:
//www.nypl.org/blog/2014/07/31/networked-catalog (visité le 19/08/2024). - La navigation interactive est disponible en suivant ce lien : http://catalog-network.
s3-website-us-east-1.amazonaws.com/ - R. Lapôtre, « Visualiser les données du catalogue »…, § 23.
- Propos rapportés par Denise Barcella
- Hakim Hachour, « De la fouille à la visualisation de données : un processus interprétatif », I2D
- Information, données & documents, 52–2 (2015), Place : Paris Publisher : A.D.B.S., p. 42-43, doi :
10.3917/i2d.152.0042, § 3. - « Concept ou angle d’approche permettant de comprendre, d’analyser, d’interpréter ou encore de
critiquer un texte, une oeuvre, ou un phénomène. » – Wikictionnaire - F. Windhager, P. Federico, E. Mayr, G. Schreder et Michael Smuc, « A Review of Information
Visualization Approaches and Interfaces to Digital Cultural Heritage Collections » (), p. 76. - Ibid., p. 77.
- Id., « Orchestrating Overviews… », p. 5.
- Ibid., pp. 5-6.
- Ibid., p. 6.
- Chronicling America Maps and Visualizations – National Digital Newspaper Program (Library of
Congress), url : https://www.loc.gov/ndnp/data-visualizations/ (visité le 19/08/2024), tableau
de bord accessible en suivant l’url suivante https://public.tableau.com/app/profile/chronicling.
america/viz/ChroniclingAmericaTemporalCoveragebyStateMap/TemporalStateCoverage. - Canton produisant 90 % des abricots Helvètes
- Id., « Orchestrating Overviews… », p. 7.
- Ibid., (cité dans).
- Ibid., p. 9.
- Mélanie Plouviez, Philosophie de l’héritage : le projet Philherit, Penser la découvrabilité des
contenus culturels, 20 juin 2023, url : https://www.bnf.fr/fr/agenda/penser-la-decouvrabilitedes-
contenus-culturels. - impresso | Media Monitoring of the Past, url : https://impresso-project.ch/app/ (visité le
19/08/2024). - Id., Philosophie de l’héritage : le projet Philherit, Paris, France, juin 2023, url : https://www.
bnf.fr/fr/agenda/penser-la-decouvrabilite-des-contenus-culturels. - En traitement automatique du langage naturel, BERT, acronyme anglais de Bidirectional Encoder
Representations from Transformers, est un modèle de langage développé par Google en 2018 –
Wikipédia - Il nous a été impossible de trouver une image de bonne qualité de cette interface, elle est tout de
même visible dans la vidéo suivante : https://youtu.be/4zaebvULdc4?t=4787 à 1h19 et 47 secondes. - Ibid.
- Michel Foucault, L’archéologie du savoir, Paris, 2008 (Tel, 354).
- M. Plouviez, Philosophie de l’héritage : le projet Philherit…
- Dans 3 des 4 langues nationales suisses (Français, Italien, Allemand [le Romanche étant exclu])
et en Luxembourgeois - Maud Ehrmann, « Explorer la presse numérisée : le projet Impresso », 129/2021 (27 nov. 2021),
p. 159-173, url : https://infoscience.epfl.ch/handle/20.500.14299/185588 (visité le 19/08/2024). - Marten Düring, Estelle Bunout et Daniele Guido, « Transparent generosity. Introducing the
impresso interface for the exploration of semantically enriched historical newspapers », Historical Methods
: A Journal of Quantitative and Interdisciplinary History, 57–1 (2 janv. 2024), p. 20-40, doi :
10.1080/01615440.2024.2344004, pp. 5-7. - Un n-gramme est une sous-séquence de n éléments construite à partir d’une séquence donnée –
Wikipédia. - La révolte des abricots de 1953 : des citoyens saxonains revalorisent un épisode de l’histoire
agricole valaisanne, Canal9, Section : ACTUALITÉS, 25 sept. 2018, url : https://canal9.ch/fr/larevolte - des – abricots – de – 1953 – des – citoyens – saxonains – revalorisent – un – episode – de –
lhistoire-agricole-valaisanne/ (visité le 19/08/2024). - Id., « Transparent generosity. Introducing the impresso interface for the exploration of semantically
enriched historical newspapers »…, pp. 5-7. - JSON, pour javascript object notation est un format communément usé pour l’échange de données
sur le web - Reconnaissance optique des caractères
- Ibid., pp. 1-2.
Bibliographie
Nb. Cette bibliographie est globale à cet article et à tous ceux sur le thèmes des interfaces.
(s. a.), Internet n’est pas assez développé pour former l’IA, mais une solution existe : les fausses données, Forbes France, 29 juill. 2024, url : https://www.forbes.fr/technologie/internet-nest-pas-assez-developpe-pour-former-lia-mais-une-solution-existe-les-fausses-donnees/ (visité le 19/08/2024).
Bermès (Emmanuelle), « Vers de nouveaux catalogues ? Propos introductif », dans Vers de nouveaux catalogues, ISSN : 0184-0886, Paris, 2016 (Bibliothèques), p. 9-12, doi : 10.3917/elec.berme.2016.01.0009.
— Le futur de la recherche documentaire : RAG time ! | Figoblog, Figoblog, 30 mars 2024, url : https://figoblog.org/2024/03/30/le-futur-de-la-recherchedocumentaire-rag-time/ (visité le 19/08/2024).
Brunet (Isabelle), Capot (Stéphane), Buset (Marc) et Moreau (Charles), Les archives du Lot-et-Garonne en route vers le IIIF, Journée d’étude internationale IIIF, 30 nov. 2023.
Carré-Marillonnet (Fabien) et Aymonin (David), « Transition bibliographique : 7 ans plus tard, où en sommes-nous ? », Archimag, 357–7 (2022), p. 36-37, doi : 10.3917/arma.357.0036.
Chronicling America Maps and Visualizations – National Digital Newspaper Program (Library of Congress), url : https://www.loc.gov/ndnp/data-visualizations/ (visité le 19/08/2024).
Clavey (Martin), La BNF : un réservoir de données pour les IA, Next, 27 juin 2024, url : https://next.ink/142051/la-bnf-un-reservoir-de-donnees-pour-les-ia/ (visité le 19/08/2024).
Dribault Dujardin (Claire Marie), Fackler (Dominique) et Pichon (Jeannette), « L’évolution des pratiques de description des archives documentaires de l’Institut national de l’audiovisuel (INA) à l’ère du numérique », 2020, Publisher : Persée – Portail des revues scientifiques en SHS, doi : 10.3406/gazar.2020.5948.
Düring (Marten), Bunout (Estelle) et Guido (Daniele), « Transparent generosity. Introducing the impresso interface for the exploration of semantically enriched historical newspapers », Historical Methods: A Journal of Quantitative and Interdisciplinary History, 57–1 (2 janv. 2024), p. 20-40, doi : 10.1080/01615440.2024.2344004.
Ehrmann (Maud), « Explorer la presse numérisée : le projet Impresso », 129/2021 (27 nov. 2021), p. 159-173, url : https://infoscience.epfl.ch/handle/20.500.14299/185588 (visité le 19/08/2024).
Entraîner une intelligence artificielle avec des données générées par IA conduit à l’absurde – Le Temps, url : https://www.letemps.ch/sciences/entrainer-une-ia-avecdes-donnees-d-ia-conduit-a-l-absurde (visité le 19/08/2024).
Etats-Unis : un Américain noir arrêté à tort à cause de la technologie de reconnaissance faciale, url : https://www.lemonde.fr/international/article/2020/06/24/un-americain-noir-arrete-a-tort-a-cause-de-la-technologie-de-reconnaissance-faciale_6044073_3210.html (visité le 19/08/2024).
Foucault (Michel), L’archéologie du savoir, Paris, 2008 (Tel, 354).
Gilman (Benjamin Ives), « Museum Fatigue », The Scientific Monthly, 2–1 (1916), Publisher : American Association for the Advancement of Science, p. 62-74, url : https://www.jstor.org/stable/6127 (visité le 19/08/2024).
Hachour (Hakim), « De la fouille à la visualisation de données : un processus interprétatif », I2D – Information, données & documents, 52–2 (2015), Paris, A.D.B.S., p. 42-43, doi : 10.3917/i2d.152.0042.
impresso | Media Monitoring of the Past, url : https://impresso-project.ch/app/ (visité le 19/08/2024).
La révolte des abricots de 1953 : des citoyens saxonains revalorisent un épisode de l’histoire agricole valaisanne, Canal9, ACTUALITÉS, 25 sept. 2018, url : https://canal9.ch/fr/la-revolte-des-abricots-de-1953-des-citoyens-saxonains-revalorisent-un-episode-de-lhistoire-agricole-valaisanne/ (visité le 19/08/2024).
Lapôtre (Raphaëlle), « Visualiser les données du catalogue », dans Vers de nouveaux catalogues, ISSN : 0184-0886, Paris, 2016 (Bibliothèques), p. 37-47, doi : 10.3917/elec.berme.2016.01.0037.
Leresche (Françoise), « La Transition bibliographique », dans Vers de nouveaux catalogues, ISSN : 0184-0886, Paris, 2016 (Bibliothèques), p. 49-67, doi : 10.3917/elec.berme.2016.01.0049.
Liem (Johannes), Kusnick (Jakob), Beck (Samuel), Windhager (Florian) et Mayr (Eva), A Workflow Approach to Visualization-Based Storytelling with Cultural Heritage Data, 17 oct. 2023, arXiv : 2310.13718 [cs], url : http://arxiv.org/abs/2310.13718 (visité le 19/08/2024).
Mesguich (Véronique), « 5. De nouveaux chemins pour accéder aux ressources », dans Bibliothèques : le Web est à vous, ISSN : 0184-0886, Paris, 2017 (Bibliothèques), p. 105-143, url : https://www.cairn.info/bibliotheques-le-web-est-a-vous–9782765415213-p-105.htm (visité le 19/08/2024).
Miller (Matt), The Networked Catalog | The New York Public Library, 31 juill. 2014, url : https://www.nypl.org/blog/2014/07/31/networked-catalog (visité le 19/08/2024).
Néroulidis (Ariane), Le crowdsourcing appliqué aux archives numériques : concepts, pratiques et enjeux, Mémoire de Master, Lyon, Université de Lyon, ENSSIB, 2015, url : https://www.enssib.fr/bibliotheque-numerique/documents/66008-le-crowdsourcing-applique-aux-archives-numeriques-concepts-pratiques-etenjeux.pdf (visité le 19/08/2024).
Noel (William), William Noel : Revealing the lost codex of Archimedes | TED Talk, 12 mai 2021, url : https://www.ted.com/talks/william_noel_revealing_the_lost_codex_of_archimedes?subtitle=en (visité le 19/08/2024).
Overall Aims – InTavia, url : https://web.archive.org/web/20231207162031/https:/intavia.eu/overall-aims/ (visité le 19/08/2024).
Penser la découvrabilité des contenus culturels, juin 2023, url : https://www.bnf.fr/fr/agenda/penser-la-decouvrabilite-des-contenus-culturels (visité le 19/08/2024).
Pillaud (Hervé), « Et si l’intelligence artificielle nous faisait changer de logique ? », Paysans & société, 405–3 (2024), Paris, Revue Paysans et Société, p. 25-33, doi : 10.3917/pes.405.0025.
Plouviez (Mélanie), Philosophie de l’héritage : le projet Philherit, Penser la découvrabilité des contenus culturels, 20 juin 2023, url : https://www.bnf.fr/fr/agenda/penser-la-decouvrabilite-des-contenus-culturels.
Poupeau (Gautier), « La donnée : nouvelle perspective pour les bibliothèques », dans Vers de nouveaux catalogues, ISSN : 0184-0886, Paris, 2016 (Bibliothèques), p. 159-171, doi : 10.3917/elec.berme.2016.01.0159.
Pouyllau (Stéphane) et Ollama (LLAMA2 +), Quels usages du “Retrieval-augmented generation” en SHS ?, HN Lab Log, Publisher : HN Lab, 17 mars 2024, url : https://hnlab.huma-num.fr/blog/2024/03/17/RAG/ (visité le 19/08/2024).
Robineau (Régis) et Sajdak (Cécile), Le programme IIIF 360 pour les archives, Journée d’étude internationale IIIF, 30 nov. 2023.
Shen (Jeffrey J.), A Generous Interface for the Discoverability of Text Collections, Accepted : 2023-07-31T19:38:10Z, Thesis, Massachusetts Institute of Technology, 2023, url : https://dspace.mit.edu/handle/1721.1/151417 (visité le 19/08/2024).
Bush (Vanevar), « As we may think », Life Magazine, oct. 1945, p. 112-114, url : https://worrydream.com/refs/Bush_1945_-_As_We_May_Think_(Life_Magazine).pdf (visité le 21/08/2024).
Windhager (Florian), Federico (Paolo), Mayr (Eva), Schreder (Günther) et Smuc (Michael), « A Review of Information Visualization Approaches and Interfaces to Digital Cultural Heritage Collections ».
— « Visualization of Cultural Heritage Collection Data : State of the Art and Future Challenges », IEEE Transactions on Visualization and Computer Graphics, 25–6 (1er juin 2019), p. 2311-2330, doi : 10.1109/TVCG.2018.2830759.
— « Orchestrating Overviews : A Synoptic Approach to the Visualization of Cultural Collections », Open Library of Humanities, 4–2 (13 août 2018), p. 9, doi : 10.16995/olh.276.

Laisser un commentaire