
Naviguer dans l’océan du web : l’importance du référencement
« Le meilleur moyen de cacher un cadavre, c’est de le mettre en page 2 des résultats sur Google » 1, cette phrase, quoique assez provocante, illustre assez bien l’importance pour un contenu d’être placé en tête des résultats de recherche. Pour ce faire, les professionnels de ce qu’on appelle le référencement utilisent deux stratégies : le SEO (Search Engine Optimization), l’optimisation de la page pour qu’elle soit mieux affichée dans les résultats de recherche, et le SMO (Social Media Optimization), l’optimisation du contenu sur les réseaux sociaux pour qu’il génère plus de clics et soit plus vu (on parle de facteurs sociaux). C’est là le premier enjeu autour de la repérabilité : pour qu’un contenu patrimonial ou un site soit repéré, il faut avant tout qu’il soit bien placé dans les résultats de recherche. Nous diviserons notre propos sur ce sujet en deux temps : d’abord « parler aux machines », où nous évoquerons les enjeux techniques spécifiques aux contenus patrimoniaux pour leur référencement ; puis « parler aux humains », où nous évoquerons les enjeux de communication et de valorisation.
Parler aux machines
« Rendre une information découvrable, dans un monde numérique, c’est la rendre accessible sous forme de données, la lier à d’autres informations pour que nos traces numériques se déploient, à l’image des réseaux de neurones dans le corps humain » (2).
Cette citation éclaire sur l’importance de ce que nous appelons un dialogue avec les machines, qui est le premier levier vers la découvrabilité (en plus de celui de la disponibilité des ressources en ligne déjà mentionné). Si une ressource n’est pas visible sur les moteurs de recherche, elle aura des chances moindres d’être découverte. Il nous faut donc évoquer les enjeux techniques du référencement, et pour cela, nous devons d’abord comprendre le fonctionnement des moteurs de recherche. Nous nous focaliserons ici sur Google, car il concentre environ 90 % de part de marché (3) et que son fonctionnement illustre celui de tous les autres moteurs de recherche.
Ce qui a fait la popularité de Google dès sa création en 1998, c’est son algorithme (PageRank) qui a très sensiblement amélioré les résultats des recherches sur le web d’alors, où l’habitude était plutôt d’utiliser des annuaires tels que Yahoo, car les résultats des moteurs de recherche d’alors n’étaient que peu pertinents et très facilement falsifiables. Les créateurs de sites créaient par exemple, sous leur page web, une page blanche avec des milliers d’occurrences du terme auquel ils souhaitaient être associés pour être placés en tête des résultats (4).
L’efficacité de PageRank est possible grâce à son utilisation d’une science inventée par Eugène Garfield : la scientométrie, au départ pour faciliter le travail des chercheurs et révéler les associations entre articles scientifiques, et les classer par nombre de citations reçues (5). Traduit dans le domaine du web, plus une page a de liens pointant vers elle (on utilise souvent le terme de backlinks), plus elle sera considérée comme centrale sur un sujet et donc pertinente. Ce principe fondamental de l’algorithme de Google a depuis été complété par un nombre impressionnant et toujours mouvant de critères, estimés à plusieurs centaines : mots-clés présents sur la page, confiance accordée au site, facteurs sociaux, temps de chargement (6)… Google ne communique jamais sur ces critères afin d’éviter des pratiques d’optimisation abusives, leur conseil est toujours le même : « faites le nécessaire pour satisfaire au mieux les internautes qui visitent votre site web et ne vous préoccupez pas inutilement des algorithmes ou des paramètres utilisés par Google pour le classement » (7). En plus de produire du contenu de qualité et utile pour les internautes, Google recommande aussi des pratiques techniques et notamment l’utilisation de « données structurées ». Pour illustrer leur importance, nous allons prendre l’exemple du projet data.bnf.fr de la Bibliothèque nationale de France (BnF).
Data.bnf.fr : sortir les données du web profond
Lancé en 2009, le projet data.bnf.fr a pour objectifs de favoriser la visibilité des données de la Bibliothèque nationale de France (BnF) sur le web ; de casser les silos que constituent les multiples catalogues de l’institution en les regroupant en un point d’entrée unique ; de « faciliter la réutilisation des métadonnées par des tiers » ; de « contribuer à la coopération et l’échange de métadonnées par la création de liens entre des ressources structurées et de confiance » (8). En bref, de « rendre les données de la Bibliothèque nationale de France plus utiles sur le web ». Pour ce faire, data.bnf.fr utilise le modèle IFLA-LRM (ex. FRBR) qui est structuré synthétiquement comme suit : l’œuvre d’un auteur est manifestée dans une édition, elle même matérialisée dans un item. Par exemple, “Notre-Dame de Paris” de Victor Hugo est manifesté dans une traduction anglaise qui est éditée chez Penguin Classics et matérialisée dans un livre (9).
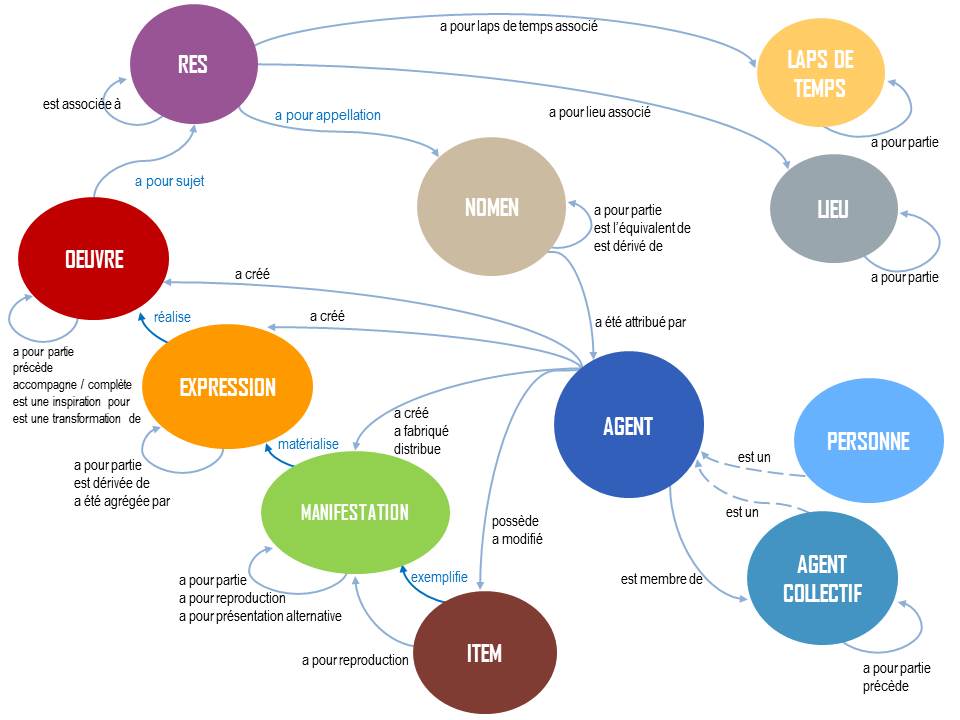
Depuis : https://data.bnf.fr/fr/semanticweb
Le site (data.bnf.fr) va donc puiser dans les différentes sources de données de la BnF, qui sont dans différents formats de données : XML-EAD, Intermarc, etc. pour ensuite les structurer selon le modèle de graph-RDF (Resource Description Framework) qui est structuré en triplets : sujet, prédicat et objet. Cela donne en suivant notre exemple de tout à l’heure : Victor Hugo (sujet) a écrit (prédicat) “Notre-Dame de Paris” (objet). L’avantage d’utiliser RDF est que l’usage des triplets facilite l’interconnexion et le partage, le modèle est souvent utilisé avec des ontologies, qui sont des descriptions formelles des concepts et des relations dans un domaine particulier, afin de standardiser et structurer les données. Cela améliore l’interopérabilité entre différentes bases de données et systèmes, et optimise le référencement des données sur le web, car cela rend plus claire leur structure pour un moteur de recherche (10). Cela permet aussi de tirer partie des fonctionnalités spéciales de recherche et notamment du knowledge graph de Google qui utilise ces triplets RDF pour créer des réseaux sémantiques d’entités et de relations, permettant à Google d’interconnecter les informations et de fournir des réponses précises et contextuelles aux utilisateurs lors de leurs recherches (11) (on parle de réponse zéro clic, voir figure 4 pour un exemple).
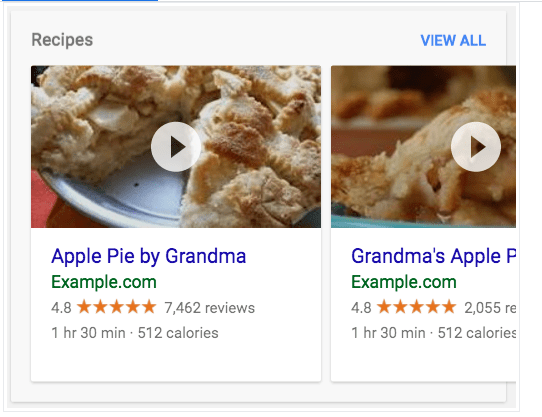
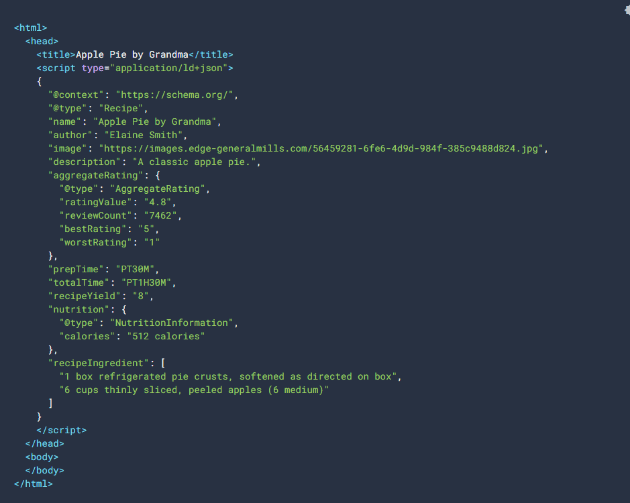
Par ailleurs, pour encore favoriser le référencement, data.bnf.fr utilise l’ontologie schema.org, créée justement par Google, Microsoft (Bing) et Yahoo (entre autres) 12 afin d’améliorer l’indexation des données. Le site met aussi en oeuvre son équivalent pour les réseaux sociaux, OpenGraph Protocol). De plus, data.bnf.fr expose ses données au format JSON-LD, qui permet encore d’améliorer l’indexation. (13).
En plus de favoriser l’indexation des ressources, data.bnf.fr utilise des identifiants uniques pour chaque ressource (URI), pérennes, qui permettent aux autres bases de données de pointer vers data.bnf.fr, et inversement. Par exemple, sur Wikidata, qui est structuré selon les mêmes principes que data.bnf.fr, la page Victor Hugo pointe vers la notice du Catalogue général de la Bibliothèque grâce à son identifiant et cette dernière pointe vers l’identifiant Wikidata de l’auteur. Outre le fait que cela génère des backlinks, cela permet aux moteurs de recherche de comprendre que le Victor Hugo de Wikidata est le même que celui de la Bibliothèque nationale et donc de lier entre elles les données.
On l’a vu, en « parlant aux machines », data.bnf.fr a permis à ses ressources de sortir du web profond. Projet précurseur, il a été suivi par le Service interministériel des archives de France qui a lancé en 2017 le portail France archives, lequel met en œuvre les mêmes principes en ajoutant la fédération des fonds sur tout le territoire (ce que fait le Catalogue collectif de France pour la Bibliothèque nationale de France). Force est de constater que les deux projets améliorent grandement le référencement. Si je tape par exemple “capitale du Dauphiné”, c’est un extrait de Gallica qui m’est proposé par Google ; si un utilisateur fait la recherche suisnvate : « archives Simone Veil », France Archives, le portail français des archives (14), apparaît en deuxième position derrière une communication autour de l’exposition consacrée à Simone Veil par les archives nationales.
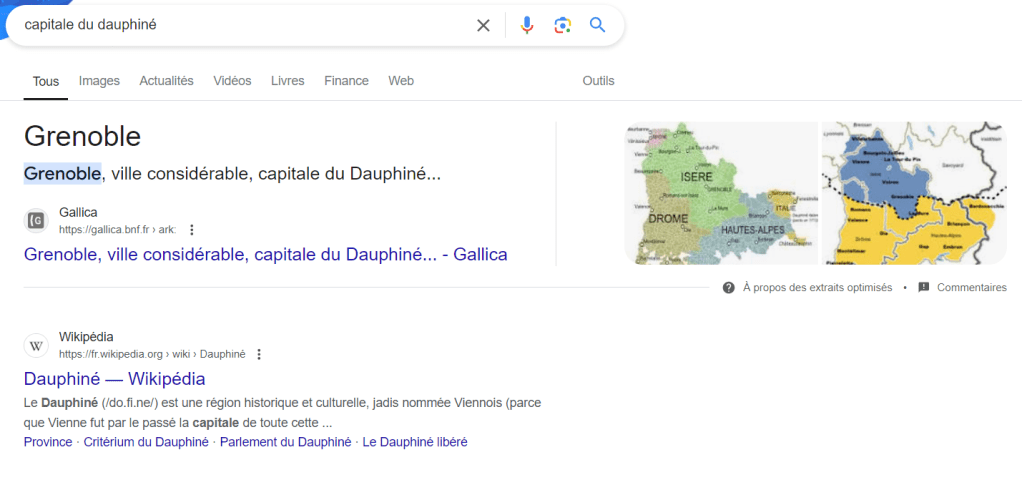
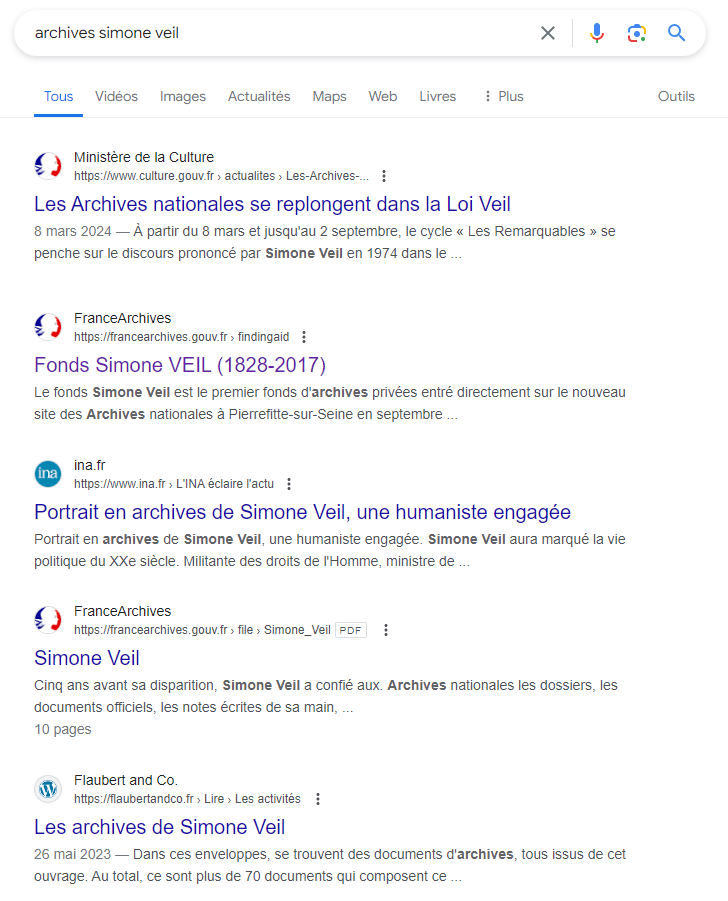
En observant les résultats, on note deux choses : d’abord, Google génère automatiquement des réponses aux questions des utilisateurs (on parle alors de réponse zéro clic), parfois en se basant sur les données de la BnF, car les données du Knowledge graph utilisées pour afficher ces questions utilisent les mêmes formats (JSON-LD) (15) que ceux mis en œuvre par data.bnf.fr, mais surtout, les deux reposent sur les principes du web sémantique. D’où une « prime » accordée à ces données dans le référencement (en plus de tout ce qui a déjà été dit). Notons aussi que le premier résultat pour notre recherche sur Simone Veil est un contenu éditorialisé « pour les humains », car tout ce que nous venons de décrire est surtout utile pour que la machine comprenne bien le contenu des pages, mais est rarement consulté réellement ; en revanche, le contenu éditorial l’est plus et ce sera l’objet de notre prochaine section où nous détaillerons l’importance de la valorisation patrimoniale dans une stratégie de référencement en prenant l’exemple de la RTS.
Parler aux humains : l’exemple des archives de la RTS
Si la stratégie technique de valorisation des contenus patrimoniaux est essentielle comme décrite plus haut, car elle permet aux machines de bien comprendre le contenu et les données, cette dernière n’aurait que bien peu d’intérêt si elle n’était pas accompagnée d’une stratégie de valorisation humaine : il est inutile de bien référencer une page dont le contenu est uniquement brut. Par ailleurs, les moteurs de recherches valorisent un contenu utile et de qualité et les réseaux sociaux sont bien souvent la porte d’entrée vers les sites web tout en améliorant leur référencement (16). Dans cette section, nous nous concentrerons sur la stratégie de valorisation des archives de la RTS, car elle nous semble rassembler les grands enjeux du domaine : un fonds au volume immense, des publics variés, et un environnement très concurrentiel. (17)
La “Bibliothèque de l’Honnête Homme” comme stratégie de valorisation
Avec environ 1 million d’heures d’archives, dont les trois quarts sont audios, la RTS dispose d’une collection très riche. Cependant, ce n’est pas sans poser de problèmes, comme évoqués dans notre première partie : l’impossibilité d’appréhender dans leur totalité des objets culturels complexes générant une Fatigue muséale qu’il est difficile de contrer « much like death and taxes » (18).
Même si elle en aurait la possibilité 19, la RTS fait le choix de ne pas donner à voir toute sa collection : ni sur le site dédié, ni sur les réseaux sociaux qu’elle anime, consciente du fait que montrer la masse documentaire presque infinie noierait les documents dits intéressants. La stratégie est donc celle d’une éditorialisation et d’une contextualisation riche, le défi est donc, comme le notent F. Windhager et al. (trad.) « de rendre les collections compréhensibles malgré une vision limitée et à des capacités d’attention restreintes » (20).
Ainsi, le site(21) est organisé comme une « Bibliothèque de l’Honnête Homme »(22) : suivant quelques thématiques, avec à chaque fois un nombre relativement restreint d’archives toujours éditorialisées, parfois assez sommairement, parfois de façon détaillée suivant une écriture journalistique (23), favorisant le référencement. Par ailleurs, les rebonds entre différents documents sont favorisés de deux manières : leur classement dans des dossiers thématiques et les recommandations, manuelles, faites par les documentalistes (nous reviendrons en détail sur la notion de recommandation).

L’importance du SMO (social media optimisation)
En 2024, sur les 5,35 milliards d’utilisateurs que compte le web, 5,04 milliards disposent d’un compte sur un réseau social (24). Il est évident qu’il est impossible de les ignorer dans une stratégie de repérabilité et de référencement. C’est doublement vrai, car, d’abord — comme évoqué plus haut — une présence efficace sur les réseaux sociaux améliore le référencement dans les moteurs de recherche, on parle de SMO (social media optimisation) ; ensuite, être visible sur ces derniers génère un nombre non négligeable de clics vers les contenus, car ils représentent un tiers du temps passé en ligne (25).
Dans le cas des archives de la RTS, ce sont clairement les réseaux sociaux qui sont le principal canal de diffusion des archives et de réception. L’institution est présente sur Facebook (490 000 followers), Instagram (115 000 followers), YouTube (607 000 abonnés), suivant la fameuse phrase de Marshall McLuhan « The medium is the message » (26) : chaque plateforme a un contenu unique et adapté. Ainsi, Instagram est alimenté en contenus courts, YouTube est le canal des formats longs, et Facebook des formats de moyenne durée. Par ailleurs, les archives sont publiées au format horizontal (plus adapté pour une consultation sur ordinateur) sur toutes les plateformes sauf Instagram, qui cible clairement un public plus jeune, sur son smartphone.
Notes
- Il est très difficile de trouver un auteur à cette citation, très présente sur le web
chez les professionnels du référencement. Elle a été lue sur https://www.linkedin.com/pulse/
le-meilleur-endroit-pour-cacher-un-cadavre-est-%C3%A0-la-page-loubier-/ sans pouvoir l’attribuer avec certitude à l’auteur de l’article.
2
- Josée Plamondon, Bien documenter pour favoriser la découverte en ligne : travailler avec les métadonnées, rapp. tech., Canada, Fondation Jean-Pierre Perreault, 2019,
https://numerique.banq.qc.ca/patrimoine/details/52327/4020619, pp. 13-14, cité dans Rapport – Mission franco-québécoise sur la découvrabilité en ligne des contenus culturels francophones,
Ministères de la Culture de la France et du Québec, France, Québec, Ministère de la Culture,
2020, p. 60, https://www.culture.gouv.fr/Media/medias-creation-rapide-ne-pas-supprimer/
Rapport-Mission-franco-quebecoise-sur-la-decouvrablilite-en-ligne-des-contenus-culturels-francophonpdf. - Search Engine Market Share France | Statcounter Global Stats, url : https://gs.statcounter.
com/search-engine-market-share/all/france (visité le 19/08/2024). - Dominique Cardon, « Dans l’esprit du PageRank. Une enquête sur l’algorithme de Google »,
Réseaux, 177–1 (2013), p. 63-95, doi : 10.3917/res.177.0063, § 4.
- Ibid., § 5.
- O. Ertzscheid, Économie des biens culturels, cours de 2e année de DUT information et communication option métiers du livre et du patrimoine…
- Présentation du fonctionnement du balisage de données structurées | Google Search Central
| Documentation | Google for Developers, url : https : / / developers . google . com / search /
docs/appearance/structured-data/intro-structured-data?hl=fr#search-appearance (visité
le 19/08/2024). - À propos de data.bnf.fr, s.d. url : https://data.bnf.fr/fr/about (visité le 16/07/2024).
- E. Bermès, Modélisation et requêtage, cours de 2e année de Master technologies numériques
appliquées à l’histoire, 2023.
- Web sémantique et modèle de données, url : https://data.bnf.fr/fr/semanticweb (visité le
18/07/2024). - Google, Introducing the Knowledge Graph, 2012, url : https://www.youtube.com/watch?v=
mmQl6VGvX-c (visité le 29/08/2024).
- About – Schema.org, url : https://schema.org/docs/about.html (visité le 19/08/2024).
- Présentation du fonctionnement du balisage de données structurées | Google Search Central | Documentation | Google for Developers…
- Nous reviendrons en détails sur la question des portails dans notre partie 2
- API Google Knowledge Graph Search | Knowledge Graph Search API, url : https : / /
developers.google.com/knowledge-graph?hl=fr (visité le 19/08/2024).
- Laura, 5 impacts des réseaux sociaux sur le SEO en 2024 ? – Redacteur Blog, avr. 2022, url :
https://www.redacteur.com/blog/impact-reseaux-sociaux-seo/ (visité le 19/08/2024). - Josée Plamondon, Bien documenter pour favoriser la découverte en ligne : travailler avec les métadonnées, rapp. tech., Canada, Fondation Jean-Pierre Perreault, 2019,
url : https://numerique.banq.qc.ca/patrimoine/details/52327/4020619, p. 14.cité dans :
Rapport – Mission franco-québécoise sur la découvrabilité en ligne des contenus culturels
francophones, Ministères de la Culture de la France et du Québec, France, Québec, 2020,
p. 60, https://www.culture.gouv.fr/Media/medias-creation-rapide-ne-pas-supprimer/
Rapport-Mission-franco-quebecoise-sur-la-decouvrablilite-en-ligne-des-contenus-culturels-francophonpdf - Bitgood, 2009, cité dans Windhager (Florian), Salisu (Saminu), Schreder (Günther) et Mayr
(Eva), « Orchestrating Overviews : A Synoptic Approach to the Visualization of Cultural Collections »,
Open Library of Humanities, 4–2 (août 2018), doi:10.16995/olh.276. - Hors quelques archives dont les droits ne lui appartiennent pas.
- F. Windhager, S. Salisu, G. Schreder, et al., « Orchestrating Overviews… », p. 3.
- https://www.rts.ch/archives/
- Jean-Marc Chatelain, « La politesse des livres », dans La Bibliothèque de l’honnête homme :
Livres, lecture et collections en France à l’âge classique, Paris, 2003 (Conférences et Études), p. 105-144,
doi : 10.4000/books.editionsbnf.2489. - https://www.rts.ch/archives/grands-formats/9614551-on-a-tue-bob-kennedy.html
- Internet et réseaux sociaux : nombre d’utilisateurs 2024 | Statista, url : https://fr.ista.
com/statistiques/1350675/nombre-utilisateurs-internet-reseaux-sociaux-monde/ (visité le
19/08/2024). - DIGITAL REPORT – LES DERNIERS CHIFFRES DU NUMÉRIQUE – OCTOBRE 2023 –
We Are Social France, url : https://wearesocial.com/fr/blog/2023/10/digital-report-lesderniers-chiffres-du-numerique-octobre-2023/ (visité le 19/08/2024). - Le médium c’est le message — Wikipédia, url : https://fr.wikipedia.org/wiki/Le_m%C3%
A9dium_c%27est_le_message (visité le 19/08/2024).
Bibiliographie
À propos de data.bnf.fr, s.d. url : https://data.bnf.fr/fr/about (visité le 16/07/2024).
About – Schema.org, url : https://schema.org/docs/about.html (visité le 19/08/2024).
About Me, oct. 2017, url : https://www.apriljoyner.com/ (visité le 19/08/2024).
API Google Knowledge Graph Search | Knowledge Graph Search API, url : https :
//developers.google.com/knowledge-graph?hl=fr (visité le 19/08/2024).
BARCELLA (Denise), Entretien avec Denise Barcella, experte patrimoine des archives
de la RTS et ancienne enseignante de l’université de Lausanne en histoire de la
télévision. Mai 2024.
Bastard (Irène) et Laborderie (Arnaud), La découvrabilité des collections numériques
patrimoniales sous l’angle des usages de Gallica, Text, juin 2023, url : https://
bbf.enssib.fr/matieres- a- penser/la- decouvrabilite- des- collectionsnumeriques – patrimoniales – sous – l – angle – des – usages – de – gallica _ 71295
(visité le 19/08/2024).
Bermès (Emmanuelle), Modélisation et requêtage, cours de 2e année de Master technologies numériques appliquées à l’histoire, 2023.
— ”De l’écran à l’émotion, quand le numérique devient patrimoine”, Paris, 2024.
Borges (Jorge Luis), La bibliothèque de Babel, 1963, url : https://baptiste-tosi.
eu/documents/la-bibliotheque-de-babel.pdf (visité le 19/08/2024)
Cardon (Dominique), « Dans l’esprit du PageRank. Une enquête sur l’algorithme de
Google », Réseaux, 177–1 (2013), p. 63-95, doi : 10.3917/res.177.0063.
Chatelain (Jean-Marc), « La politesse des livres », dans La Bibliothèque de l’honnête
homme : Livres, lecture et collections en France à l’âge classique, Paris, 2003 (Conférences et Études), p. 105-144, doi : 10.4000/books.editionsbnf.2489.
Conseil de la radiodiffusion et des télécommunications canadiennes (CRTC)
et l’Office national du film du Canada (ONF), Le contenu à l’ère de l’abondance, sommet sur la découvrabilité des contenus culturels canadiens, 2016, url :
https://web.archive.org/web/20171027015812/http:/decouvrabilite.ca/
videos/resume-sommet-decouverabilite/.
Durand (Emmanuel), L’attaque des clones : la diversité culturelle à l’ère de l’hyperchoix,
Paris, 2016 (Nouveaux débats, 44).
Ertzscheid (Olivier), Économie des biens culturels, cours de 2e année de DUT information et communication option métiers du livre et du patrimoine, 2019.
— GPT-4 Omni : Chat Pantin(s). Mai 2024, url : https://affordance.framasoft.
org/2024/05/gpt-4-omni-chat-pantins/ (visité le 19/08/2024).
Ertzscheid (Olivier) et Gallezot (Gabriel), « Chercher faux et trouver juste, » ( juill.
2003).
Europeana, url : https://www.bnf.fr/fr/europeana (visité le 19/08/2024).
Get More Eyes on Your Content Using StumbleUpon, déc. 2012, url : https://verticalresponse.com/blog/stumbleupon-gets-great-content-seen/ (visité le 19/08/2024).
Godin (Christian), « « La culture pour chacun » : une nouvelle politique culturelle ? »,
Cités, 45–1 (2011), p. 164-168, doi : 10.3917/cite.045.0164.
Google, Introducing the Knowledge Graph, 2012, url : https://www.youtube.com/
watch?v=mmQl6VGvX-c (visité le 29/08/2024).
Histoire, url : https://memoriav.ch/fr/memoriav/histoire/ (visité le 19/08/2024).
Introduction to clustering | Machine Learning | Google for Developers, url : https:
//developers.google.com/machine-learning/clustering (visité le 19/08/2024).
Laura, 5 impacts des réseaux sociaux sur le SEO en 2024 ? – Redacteur Blog, avr. 2022,
url : https://www.redacteur.com/blog/impact-reseaux-sociaux-seo/ (visité
le 19/08/2024).
Luneteau (Bastien) et Lecomte (Valentin), Penser la découvrabilité des contenus culturels, juin 2023, url : https://www.bnf.fr/fr/agenda/penser-la-decouvrabilitedes-contenus-culturels (visité le 19/08/2024).
Marx (William), Le rêve de la bibliothèque parfaite : épisode • 4/10 du podcast Les
bibliothèques invisibles | France Culture, url : https : / / www . radiofrance . fr /
franceculture/podcasts/les-cours-du-college-de-france/le-reve-de-labibliotheque-parfaite-7100321 (visité le 19/08/2024).
Meuret (Laure), Entretien avec Laure Meuret, chargée d’archivage de l’information pour
le secteur radio (RTS), mai 2024.
Ministères de la Culture (France et Québec), Rapport – Mission franco-québécoise
sur la découvrablilité en ligne des contenus culturels francophones, rapp. tech., France,
Québec, Ministère de la Culture, 2020, p. 60, url : https://www.culture.gouv.fr/
Media/medias-creation-rapide-ne-pas-supprimer/Rapport-Mission-francoix
quebecoise- sur- la- decouvrablilite- en- ligne- des- contenus- culturelsfrancophones.pdf.
Présentation du fonctionnement du balisage de données structurées | Google Search Central
| Documentation | Google for Developers, url : https://developers.google.
com/search/docs/appearance/structured-data/intro-structured-data?hl=
fr#search-appearance (visité le 19/08/2024).
Stratégie commune de la mission franco-québécoise sur la découvrabilité des contenus
culturels francophones | Gouvernement du Québec, url : https://www.quebec.ca/
gouvernement/ministere/culture-communications/publications/strategiecommune-mission-franco-quebecoise-decouvrabilite-contenus-culturelsfrancophones (visité le 19/08/2024).
Web sémantique et modèle de données, url : https://data.bnf.fr/fr/semanticweb
(visité le 18/07/2024).
Windhager (Florian), Salisu (Saminu), Schreder (Günther) et Mayr (Eva), « Orchestrating Overviews : A Synoptic Approach to the Visualization of Cultural Collections », Open Library of Humanities, 4–2 (août 2018), doi : 10.16995/olh.276

Répondre à mgriveau Annuler la réponse.